
Using Regular Expressions
Regular expressions is an important tool in the parsing of data. While modern audit systems often express output in JavaScript Object Notation (JSON), there are times that the data is in a formatted string and needs to be extracted into fields to make the information searchable for analysis.
Resources
RegexLearnis a site to teach regular expressions from the ground up.
I am going use Regex101 (regular expressions 101) website to write and validate expressions for parsing.
There are many cheat sheets out here for regex, here is one.
Basics
Character Classes
Character Classes save us the time of listing all the character variation to common patterns and special cases.
Parsing tends to use \d, /S and \w.
| Character Class | Description |
|---|---|
| . | Any character |
| \d | A digit: [0-9] |
| \D | A non-digit: [\^0-9] |
| \s | A whitespace character: [ \t\n\x0B\f\r] |
| \S | A non-whitespace character: [\^\s] |
| \w | A word character: [a-zA-Z_0-9][a-zA-Z_0-9] |
| \W | A non-word character: [\^\w] |
Boundary Matches
Boundary matches help with focusing where the match is starting and ending. When parsing, we tend to want to have the start ^ and end of the line $ as part of the match.
Quantifiers
The quantifiers handle the repetition of a patters. The most common is the plus +, which means there is at least one member to the match and then there can be more. Next The is the asterisk * that means zero (not at all) or more of the pattern. The asterisk is often abused. Finally, the question mark ?. This is when we have an optional value. At first, this seems not that useful, but it becomes very useful when two patterns only are different by an additional value.
| Quantifiers | Description |
|---|---|
| . | Matches zero or more occurrences. |
| + | Matches one or more occurrences. |
| ? | Matches zero or one occurrence. |
Common Mistake
Try to never start a regular expression with a quantifier. This will make the pattern searching extremely slow. Programmers call such pattern strings regex-of-death, for the can make systems halt and fail on timeout.
Named Placeholder
Lastly, we want to map grouped patterns into a JSON object. To do this, we use named place holders. They look like this: (?P<group_name>…)
Within parenthesis, we state a grouping with a place holder ?P If you read ChatGPT section, you will see many it will not do this by default. But we want these to be named. The name in the JSON object will be the group name that we provide. The pattern after the > (represented here with three dots) is where we place the pattern that we are matching.
Easy Example
A Linux process called Multipath produces an audit message of:
sda: failed to get sgio uid: No such file or directory
We can first parse this by the matching the disk drive and capturing the message. Try along by opening the regex100 site and pasting in the message.
We start by first noting the start of the line ^and we can add the drive. Notice that the interface starts highlighting the match.
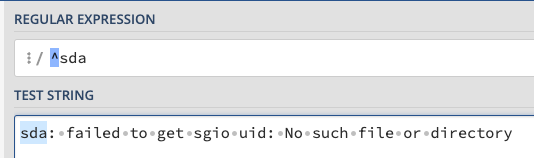
Let's match all the way up to the message. We could type : and the regex will understand it, but it is a good habit to escape punctuation by placing a backslash \in front of it.
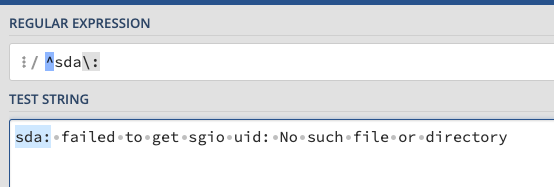
We never type spaces. They are hard for people to see and count. Instead, we use the charter class \s which represents the space. You will normally see a person add the + meaning I want at least one space, but will consider more than one. This addresses with the next pattern accidentally starts with spaces.
Now we are up to the message itself. We want to capture that. This is where we use the grouped placeholder. Seems like we could just the + or * sign. But the problem is that a group needs at least one token. This pattern gets us the token and address the fact there is a non-word character in the message (the : prevents us from using the word class).
(?<msg>[\S\s]+)
Finally, we say that we are at the end of the pattern.
^sda\:\s+(?<msg>[\S\s]+)$If you were following along, you would have seen the system highlight the matching and provide details on the matching to include the grouping.
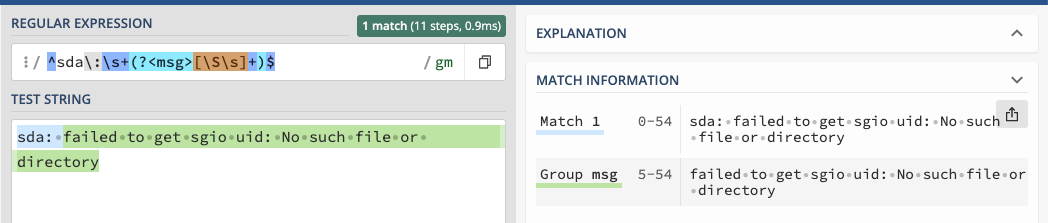
In our code we will be placing this into a variable.
let log = regexp(^`sda\:\s+(?<msg>[\S\s]+)$`, message)The pattern is encased with backticks not single quotes. This allows us not to have to escape the characters in the expression.
Options
Understanding what you are parsing helps. Here the sda refers to the drive. The mount might not be a. In this case, a pattern of sd\wmight be a better pattern.
^sd\w\:\s+(?<msg>[\S\s]+)$But we need to keep away from getting to fancy. We are playing with the start of a pattern which can cause search speed issues. Try to keep the start of a pattern as long as possible.
Double Patterns
Just like the movie Inception, sometimes we have patterns within patterns.
In these cases we want to match the first pattern, and then operate on the results.
JSON Placeholders
The Fluency heartbeat is a good example of this:
syslog-heartbeat {\"mgmt_service\":\"3.2.1\",\"os_version\":\"3.10.0-1160.31.1.el7.x86_64\"}
We want to extract the JSON first and then parse it with parseJson(text)
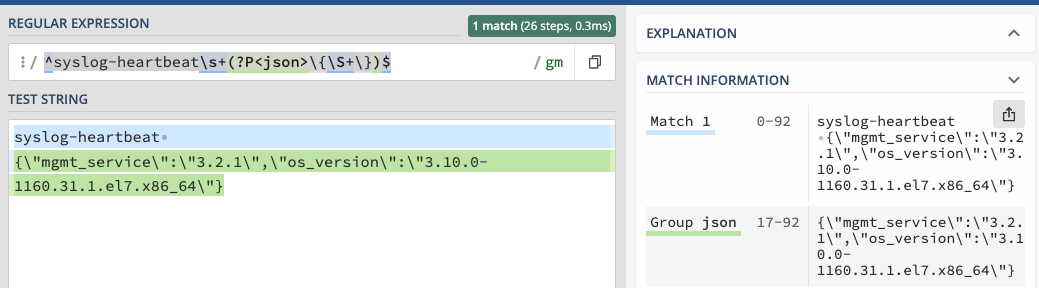
It seems common to write a pattern like: ^syslog-heartbeat\s+\{(?P<json>\S+)\}$
This pattern will match the and extract the JSON, but the curly brackets {}are not part of the placeholder. So, when you assign the value, the json attribute will not have them and parseJsonwill error out.
This is a case we want the boundary match to be inside the placeholder pattern:
^syslog-heartbeat\s+(?P<json>\{\S+\})$
Now you see the Group json has the {} as part of the returned value.
Updated over 1 year ago